Indexing towards Web 3.0
I’ve been reading two books this summer: Indexing: from Thesauri to the Semantic Web (Pierre de Keyser 2012); as well as Subject Access to Information: An Interdisciplinary Approach (Koraljka Golub, 2015).
Having worked with the Dublin Core metadata schema as a means to enhance access and retrieval of 40 years of research at the International Development Research Centre (IDRC, Ottawa, Canada), I’ve become convinced of the power of indexing as it applies to the World Wide Web. The Web Consortium (W3C) is moving towards a Semantic Web (Web 3.0), where retrieval of information becomes intelligent. Methods of indexing for context as well as content need to evolve over the next several years.
Both of the above books look forward to the Semantic Web, and how structures of knowledge and information will undergo change (KOS, XML and RDF- but more on this later). The books also examine user behaviour and how Google has informed search and retrieval practices and results. A Semantic Web would provide answers to search questions in a customized, or more tailored and human-centric manner than procuring, for instance, a thousand website landing pages to wade through, often ranked artificially.
As a member of a community of indexers and information management experts, I find along with these authors, that indexing and library science techniques have been supplanted by Information Technology experts (the IT guys in every enterprise), who are mostly oblivious to classification systems already developed and applicable to their search and retrieval problems. What I’d like to believe is that the time has come for the acknowledgement of the expertise of indexers and librarians! We exist so often in the background that we have a hard time even valuing our own experience. Re-naming ourselves as Content Management experts or Information Architects widens opportunities. Heather Hedden’s book “The Accidental Taxonomist” speaks to developments in our industry.
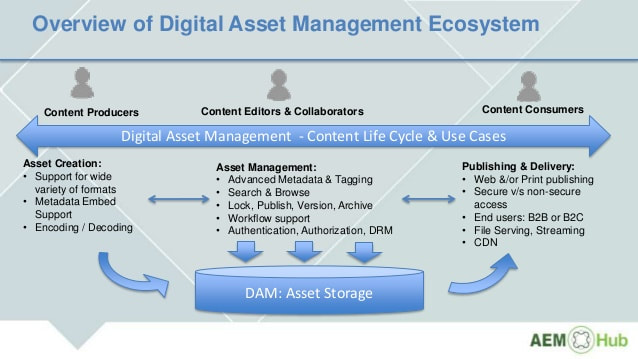
At the latest Indexing Society of Canada conference (June 2017, Montreal), a delegate from Shanghai referred to a new initiative there named “Big Data and Indexing Institute.” We need this to take root in North America, beyond the IT guys. Indexers hold knowledge key to interoperability of Big Data, Open Data, and Linked Open Data retrieval. Big Data and Indexing ought to be intrinsically related, (like the Ministry of Environment and Climate Change). Every business enterprise is currently engaged in re-sorting their digital assets so that decades of information can be stored (AND RETRIEVED) via the cloud. It’s called Digital Assets Management, and again, knowledge of indexing and information retrieval is key. And again, the IT guys are re-inventing the wheel because they don’t recognize the word “indexing” as a thing.
As you can see, just scratch the surface of this indexer, and there’s another ¾ of a (warm) iceberg beneath, just beginning to try to explain what I see happening Out There when it comes to current indexing applications.
I’m going to write more about the content of these books, but leave you with two blog sites devoted to DAM (Digital Assets Management), because it is a Thing that follows on the heels of cloud storage.
http://planetdam.org/author/90021854-ef96-4acc-8292-da83f19a3c5b
http://digitalassetmanagementnews.org/
Having worked with the Dublin Core metadata schema as a means to enhance access and retrieval of 40 years of research at the International Development Research Centre (IDRC, Ottawa, Canada), I’ve become convinced of the power of indexing as it applies to the World Wide Web. The Web Consortium (W3C) is moving towards a Semantic Web (Web 3.0), where retrieval of information becomes intelligent. Methods of indexing for context as well as content need to evolve over the next several years.
Both of the above books look forward to the Semantic Web, and how structures of knowledge and information will undergo change (KOS, XML and RDF- but more on this later). The books also examine user behaviour and how Google has informed search and retrieval practices and results. A Semantic Web would provide answers to search questions in a customized, or more tailored and human-centric manner than procuring, for instance, a thousand website landing pages to wade through, often ranked artificially.
As a member of a community of indexers and information management experts, I find along with these authors, that indexing and library science techniques have been supplanted by Information Technology experts (the IT guys in every enterprise), who are mostly oblivious to classification systems already developed and applicable to their search and retrieval problems. What I’d like to believe is that the time has come for the acknowledgement of the expertise of indexers and librarians! We exist so often in the background that we have a hard time even valuing our own experience. Re-naming ourselves as Content Management experts or Information Architects widens opportunities. Heather Hedden’s book “The Accidental Taxonomist” speaks to developments in our industry.
At the latest Indexing Society of Canada conference (June 2017, Montreal), a delegate from Shanghai referred to a new initiative there named “Big Data and Indexing Institute.” We need this to take root in North America, beyond the IT guys. Indexers hold knowledge key to interoperability of Big Data, Open Data, and Linked Open Data retrieval. Big Data and Indexing ought to be intrinsically related, (like the Ministry of Environment and Climate Change). Every business enterprise is currently engaged in re-sorting their digital assets so that decades of information can be stored (AND RETRIEVED) via the cloud. It’s called Digital Assets Management, and again, knowledge of indexing and information retrieval is key. And again, the IT guys are re-inventing the wheel because they don’t recognize the word “indexing” as a thing.
As you can see, just scratch the surface of this indexer, and there’s another ¾ of a (warm) iceberg beneath, just beginning to try to explain what I see happening Out There when it comes to current indexing applications.
I’m going to write more about the content of these books, but leave you with two blog sites devoted to DAM (Digital Assets Management), because it is a Thing that follows on the heels of cloud storage.
http://planetdam.org/author/90021854-ef96-4acc-8292-da83f19a3c5b
http://digitalassetmanagementnews.org/
 RSS Feed
RSS Feed